

“One mistake has had catastrophic results…” Nick Hyatt, director of threat intelligence at the security firm Blackpoint Cyber said in a CNBC interview just a day after the outage began.
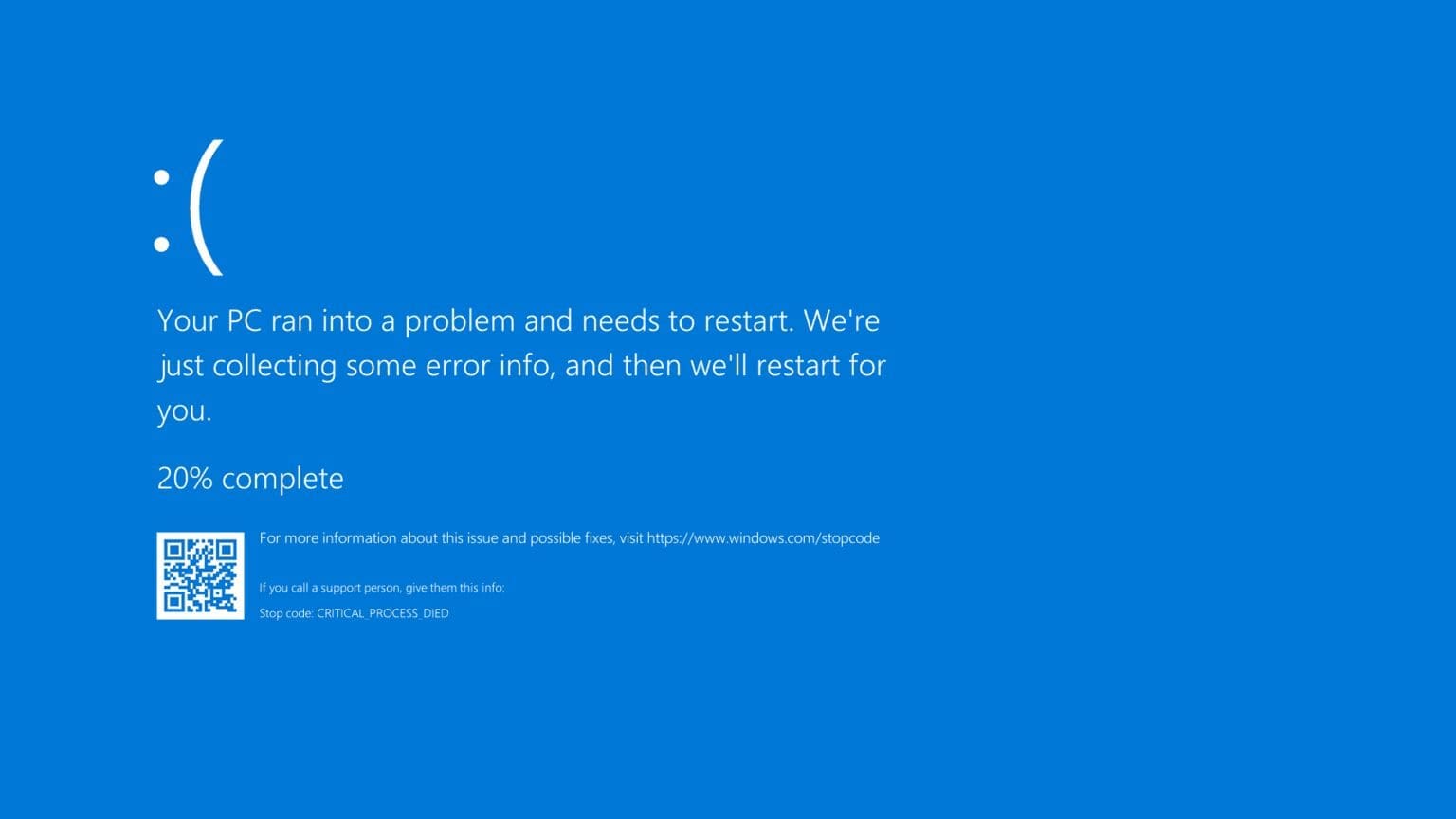
On July 19th, 2024 at approximately 12:09 am EST or 4:09 UTC, almost everything shut down. Corporations were at a standstill. There were multiple speculations as to what caused the outage; the most common being a terrorist attack. We soon found out that the failed systems shared one very important detail: they all used the same cybersecurity protection software.
Let me explain why this is important…
What is CrowdStrike?
CrowdStrike is a cybersecurity platform that offers a variety of security solutions, principally through the Falcon platform. Their primary focus is on endpoint security, which involves protecting specific devices (such as laptops, desktops, and servers) against cyber threats. The Falcon platform includes advanced capabilities such as next-generation antivirus, threat intelligence, and real-time analytics. CrowdStrike enables enterprises to successfully prevent, detect, and respond to cyberattacks by monitoring and securing endpoints. Their function is crucial in ensuring the overall cybersecurity posture and protecting sensitive data. The Falcon platform uses cloud-native architecture, artificial intelligence (AI), and machine learning (ML) to identify, prevent, and respond to cyber threats in real-time.

The Incident
CrowdStrike’s recent update failure had significant implications for businesses and users. On July 19, 2024, CrowdStrike issued a configuration update for its Falcon sensor for Windows. This upgrade inadvertently introduced a logic fault, resulting in widespread system failures and blue screens of death (BSOD) for many users. The event interrupted many organizations that relied on CrowdStrike for cybersecurity, forcing an immediate response and mitigation efforts from the corporation.
The ripple effects of the outage were horrendous. Hotels, banks, and airlines were among the larger corporations able to operate. Even some smaller corporations were battling with their routing systems for distributions and others with their cash registers. Both David and Goliath were hit with this stone.
The Concept of Single Point of Failure
A single point of failure (SPOF) is a crucial component of a system whose breakdown can disrupt the entire functioning. The CrowdStrike incident demonstrated how a single update pushed to all systems at the same time might impair a large section of their client base. This stresses the importance of robust systems designed to prevent SPOFs. Other prominent SPOF occurrences in technology include cloud service disruptions, which have already affected major platforms such as AWS and Google Cloud.
Importance of Redundancy and Backup Plans

Redundancy is vital for preventing SPOFs since it ensures that critical functions have backups. The deployment of numerous layers of security technologies and infrastructure components is one strategy for increasing redundancy. Companies like Google and Amazon demonstrate successful redundancy implementation, ensuring flawless service continuation even during partial system failures.
In addition to redundancy, verifying configuration changes in a staging environment before deploying them to the larger production system is critical. A staging environment is a copy of the production environment that allows you to securely test new modifications, upgrades, or features without disrupting live users. This approach enables extensive validation and detection of potential issues in a controlled environment.
Key steps for effective staging environment testing include:
- Create an Accurate Replica: Ensure the staging environment mirrors the production environment as closely as possible regarding hardware, software, network configurations, and data.
- Automated Testing: Implement automated tests to quickly identify any issues with the changes introduced. This includes unit tests, integration tests, and end-to-end tests.
- User Acceptance Testing (UAT): Involve end-users or stakeholders to validate the changes in the staging environment to ensure they meet business requirements and user expectations.
- Performance Testing: Assess the impact of the changes on system performance, ensuring that the system can handle expected load and stress conditions.
- Security Testing: Conduct security assessments to identify any new vulnerabilities introduced by the changes.
- Rollback Plan: Prepare a rollback plan to revert to the previous configuration if issues are identified during or after deployment to production.
While larger businesses can and should implement a staged approach to rolling out software updates where possible, there is a need to balance stability with speed when dealing with virus definition updates. Where possible, configure less essential systems to get the earliest definition updates, so that severe problems can be identified prior to causing a network outage. Don’t delay these definition updates weeks or even days; an hour or so delay should be enough time to recognize issues that would result in a complete outage.
Smaller businesses often do not have the funding and resources that would allow a staged testing environment. This makes business continuity planning even more essential for them. Have a plan for what to do if all computers suddenly cease functioning, and if there is no in-house IT, have a list of contact numbers you can call for local IT companies that could be quickly mobilized to deal with a large-scale outage.
By taking these measures and utilizing a staging environment where possible, organizations may dramatically reduce the chance of disruptions and assure smooth, dependable operations when software updates are automatically pushed out by a software vendor.
Diversifying and Selecting Cybersecurity Tools
The CrowdStrike incident illustrated the dangers of relying solely on one cybersecurity technology. A multi-layered cybersecurity approach employs a variety of tools that complement one another, such as firewalls, intrusion detection systems, and endpoint protection software, it’s important to understand that even this approach will have its limitations. Every component of the system may have come from a different manufacturer, yet the impact could have been just as disastrous because the system with a failure was linked to the kernel via a driver.
The majority of CrowdStrike-using firms were not aware that content updates were not part of their staged update settings. They believed that having N-1 on their servers would keep them safe, but that rule only applied to driver updates—not to content files. The effect was exacerbated by this misconception. Consequently, it’s critical to carefully review software vendor update rules to make sure your company knows what it may update automatically without your awareness and whether or not it can even perform safe staging for testing. It could be wise to stay away from that technology product completely if this is not understood or cannot be accomplished.
Through a thorough awareness of these subtleties and thoughtful tool selection, companies can enhance their defenses against a variety of threat vectors and reduce the probability of system failure.
Lessons Learned from the CrowdStrike Incident
Businesses can learn several key lessons from the CrowdStrike update failure:
- Plan for All Types of Outages
- Companies frequently prepare for well-known threats, such as ransomware attacks, for which the recovery procedures are well-known. However, the CrowdStrike event highlighted a different problem: Many organizations felt that they had to wait for advice from the security vendor before starting recovery processes. The main reason for this hesitancy was worries about possible data loss if previous system images were restored.
- Take Immediate Recovery Actions
- A major lesson learned is that in the event of a mass failure of all systems, whether caused by a software vendor or another reason, businesses should initiate recovery measures quickly as if they were dealing with a ransomware assault. Prioritizing system recovery is critical for corporate operations, even if it means tolerating some data loss in order to get systems back online quickly. This potential data loss can be planned for in advance by utilizing cloud backup software that frequently backs up critical files.
- Avoid Recovery Pitfalls
- Another issue encountered during the CrowdStrike attack was full drive encryption using BitLocker. Some firms have placed their BitLocker keys on a server that was both BitLocker-protected and affected by the BSOD. This meant that the BitLocker keys, which are required for recovery, were inaccessible. To avoid such dangers, ensure that crucial recovery keys and information are kept in a safe but distinct location. This idea can be paraphrased as “Don’t put all your eggs in one basket”
- Regularly update and test disaster recovery and business continuity plans
- Frequently Update and Test your Plans
- Disaster recovery and business continuity plans must be dynamic documents that adapt to the shifting threat scenario. Regular modifications are required to account for new threats, technological advancements, and lessons learned from previous disasters. Furthermore, regular testing of these plans ensures that all stakeholders understand their roles and duties during an emergency.
- Run Simulated Drills Based on Real-World Scenarios
- Simulated drills can help discover plan shortcomings and gaps. To guarantee a coordinated reaction, these drills should include not only IT personnel but also representatives from other relevant departments. Testing various scenarios, including those that simulate unexpected failures such as the CrowdStrike event, equips the business to handle a wide range of situations effectively.
- Continually Improve Your Plans
- Following each test or real-world incident, it is critical to examine the results and make any necessary changes to the plan. This continuous improvement process contributes to the development of a more resilient organization capable of continuing operations in the face of disruptions.
- Frequently Update and Test your Plans
Moving Forward: Strengthening Cybersecurity and Business Continuity
To enhance cybersecurity posture, businesses should:
- Conduct regular risk assessments and software updates.
- Invest in comprehensive employee training and awareness programs, and ensure these programs contain training on the organization’s business continuity and disaster recovery plans so that employees know what to expect.
- Regularly review and improve disaster recovery plans.
Creating an Effective Business Continuity Plan: Resources and Tools
A thorough business continuity strategy is critical for risk management and ensuring that your organization’s operations can continue amid disruptions. If your company does not already have a plan, it is critical to create one. Here are a few resources and tools to get you started:
- FEMA’s Continuity of Operations Planning Guide: Provides a detailed guide on creating continuity plans for various types of organizations, including healthcare facilities.
- Ready.gov Business Continuity Planning: Offers a step-by-step guide to developing a business continuity plan, including templates and checklists.
- Business Continuity Institute (BCI): Provides resources, training, and certification for business continuity professionals. Their website includes best practices and tools for creating and managing continuity plans.
- Sungard Availability Services – Business Continuity Planning Tools: Offers a variety of tools and templates to assist with business continuity planning.
- ISO 22301 Business Continuity Management Standard: An international standard that provides a framework for establishing and maintaining an effective business continuity management system.
Call to Action: Don’t Wait to Develop a Plan
The CrowdStrike update failure serves as an important reminder of the value of resilience in cybersecurity and commercial operations. Businesses must assess and improve their cybersecurity strategy to ensure ongoing protection and operational integrity. Resources and tools are available to help improve cybersecurity resilience and ensure preparedness for future incidents.
If your company does not already have a business continuity strategy, it is critical to create one that is feasible as quickly as possible. A well-structured plan guarantees that your firm can successfully respond to disturbances, preserve vital functions, and reduce downtime. Begin by reading and trying to understand the above information and develop a plan tailored to your organization’s needs. By investing in a strong business continuity strategy, you can protect your company from unexpected disasters and ensure a more resilient future.
If you’re still not sure where to go to get started, many Managed IT Service Providers, such as Managed Nerds can help your small business develop, implement, and test a tailored and resilient business continuity strategy.

References
Associated Press. (2024, July 22). ChaosFrom mom-and-pop payrolls to global airline traffic messes, the cleanup from the world’s biggest IT outage drags on days later. inc.com. Retrieved July 25, 2024, from https://www.inc.com/associated-press/businesses-large-small-still-sorting-out-crowdstrike-outage-chaos.html
Bci. (n.d.). The Business Continuity Institute (BCI) | A global institute for business continuity and resilience. BCI. https://www.thebci.org/
Single Points of Failure and Backup & Disaster Recovery. (2023, June 13). Consolidated Communications. https://www.consolidated.com/blog/artmid/3914/articleid/226/single-points-of-failure-and-backup-disaster-recovery
TestEnvMgt. (2023, September 20). What is a Staging Environment? Test Environment Management (DOT) Com. https://www.testenvironmentmanagement.com/what-is-a-staging-environment/
The Power of the Falcon Platform Explained | Video | CrowdStrike. (2022, December 29). crowdstrike.com. https://www.crowdstrike.com/resources/videos/the-crowdstrike-falcon-platform/
Williams, K. (2024, July 20). The CrowdStrike fail and next global IT meltdown already in the making. CNBC. https://www.cnbc.com/2024/07/20/the-crowdstrike-fail-and-next-global-it-meltdown-already-in-the-making.html
0 Comments